Site Reliability Engineering (SRE) Services

Site Reliability Engineering (SRE) Services
At iTechOps, we help businesses implement SRE best practices to achieve a highly reliable, scalable, and cost-efficient IT infrastructure. Whether you’re running cloud-native applications, DevOps pipelines, or AI-driven workloads, our SRE expertise ensures performance, security, and innovation at every level.
Schedule a Call
What We Mean by SRE
Site reliability engineering (SRE) is a culture and a set of practices to ensure system reliability and maintainability. The SRE team implements best practices, automation, and metrics to find creative solutions when sites slow to the point of user frustration. The team strikes the right balance between reliability and feature velocity.
How We Help with Site Reliability

-
1. Reliability Engineering & System Resilience
- We set Service Level Objectives (SLOs) and Service Level Indicators (SLIs) to measure and manage reliability.
- We design fault-tolerant architectures with auto-scaling, redundancy, and failover.
- We conduct chaos engineering and stress testing to ensure systems can handle failures.
-
2. Observability, Monitoring & Incident Response
- We deploy real-time monitoring, logging, and alerting using industry-leading tools.
- Our AI-driven incident response enables faster detection, diagnosis, and resolution of system issues.
- We conduct blameless post-mortems to continually enhance system resilience and reliability.
-
3. Automation & Infrastructure as Code (IaC)
- We reduce manual toil by automating infrastructure provisioning, deployments, and scaling.
- Our expertise in Terraform, Ansible, Kubernetes, and CI/CD pipelines ensures seamless automation.
- We implement self-healing mechanisms to auto-remediate common system failures.
-
4. Performance & Capacity Optimization
- We perform performance tuning, load testing, and capacity planning to optimize resource usage.
- Our solutions deliver cost-effective cloud infrastructure with optimal scaling.
- We enable edge computing and caching to enhance performance.
-
5. Security & Compliance-Driven Reliability
- We integrate security into SRE practices to ensure compliance with industry standards.
- Our solutions include automated security scans, vulnerability assessments, and incident response plans.
- We enforce zero-trust architecture, role-based access control (RBAC), and encryption for system security.
Our Process: Getting Started with SRE
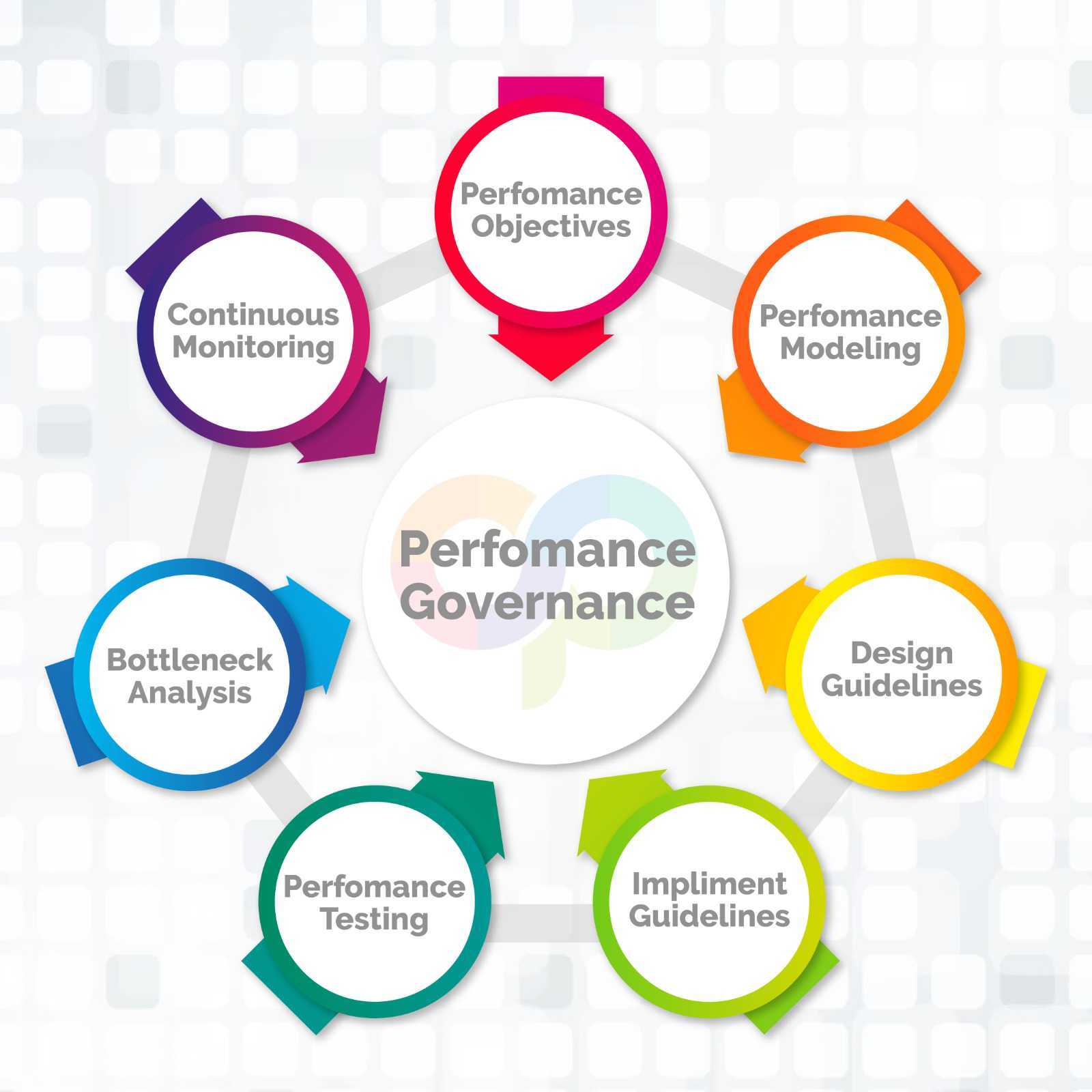
-
Step 1: Assessment & Strategy
- We analyze your current infrastructure, operations, and reliability challenges.
- We define Service Level Objectives (SLOs), Service Level Indicators (SLIs), and Error Budgets tailored to your business needs.
- We create a roadmap to align SRE practices with your DevOps, Cloud, and IT strategies.
-
Step 2: Observability & Monitoring Implementation
- We deploy industry-leading monitoring, logging, and alerting tools for real-time system insights.
- We enable AI-driven incident detection and automated response mechanisms.
- We ensure end-to-end observability for cloud, on-prem, and hybrid environments.
-
Step 3: Automation & Infrastructure as Code (IaC)
- We automate repetitive tasks, deployments, and infrastructure provisioning using Terraform, Ansible, Kubernetes, and CI/CD pipelines.
- We implement self-healing systems that auto-recover from failures.
- We optimize resource management to ensure cost-effective scaling.
-
Step 4: Performance Optimization & Scaling
- We conduct load testing, performance tuning, and capacity planning to optimize system efficiency.
- We implement auto-scaling and caching strategies to handle fluctuating workloads.
- We fine-tune databases, networks, and applications for peak performance.
-
Step 5: Incident Management & Reliability Engineering
- We establish a proactive incident response framework with automated alerts and workflows.
- We conduct blameless post-mortems to analyze incidents and implement preventive measures.
- We integrate runbooks and AI-driven remediation to reduce downtime.
-
Step 6: Continuous Improvement & Reliability Culture
- We foster an SRE mindset within your organization, enabling teams to adopt best practices.
- We conduct regular audits, feedback loops, and workshops to refine reliability strategies.
- We continuously evolve systems to meet growing demands and business objectives.
Benefits of SRE
-
1. More Reliable & Uptime
- Proactive monitoring, alerting, and automated incident response.
- SLOs and SLIs ensure performance meets business needs.
- Fault-tolerant architectures and self-healing reduce downtime.
-
2. Faster Incident Response & Recovery
- Real-time observability detects issues before they impact users.
- Automated runbooks and AI-driven incident management accelerate recovery.
- Blameless post-mortems ensure continuous improvement.
-
3. More Automation & Less Toil
- IaC and CI/CD pipelines automate deployments and scaling.
- Auto-remediation scripts fix common issues without intervention.
- Reduces manual tasks so teams focus on innovation.
-
4. Scalability & Performance Optimization
- Applications scale dynamically to handle traffic spikes.
- Performance tuning, load testing, and capacity planning maximize efficiency.
- Cost-optimized cloud strategies prevent resource wastage.
-
5. Stronger Security & Compliance
- Automated security monitoring and vulnerability scanning reduce risks.
- Ensures compliance with standards like ISO, SOC 2, HIPAA, and GDPR.
- Implements zero-trust security and encrypted communication.
-
6. Seamless DevOps Integration
- SRE bridges development and operations for better collaboration.
- Shift-left reliability ensures early performance and security.
- Increases deployment velocity while maintaining stability.
-
7. Cost Savings & Operational Efficiency
- Optimizes infrastructure spending through efficient resource management.
- Automates cloud cost analysis and prevents overuse.
- Minimizes revenue loss from downtime and system failures.
Too new to Site Reliability Engineering?
Understand what truly SRE means just by contacting us and quenching your curiosity.
Contact Our SRE ExpertFAQ
What is Site Reliability Engineering (SRE)?
- Site Reliability Engineering (SRE) is a discipline that applies software engineering principles to IT operations to improve system reliability, scalability, and performance. SRE teams use automation, monitoring, and incident response to ensure highly available and resilient infrastructure.
How does SRE differ from DevOps?
- While SRE and DevOps share similar goals, SRE focuses more on reliability, automation, and scalability through engineering-driven operations. DevOps emphasizes collaboration between development and operations teams, whereas SRE applies software engineering practices to improve system resilience.
Can small and medium businesses (SMBs) adopt SRE?
- Yes! SMBs can leverage SRE principles through automation, cloud monitoring, and outsourcing SRE expertise to ensure system reliability without large operational overhead.
How does SRE improve system reliability?
- SRE improves reliability by:
- Setting Service Level Objectives (SLOs) and Error Budgets to balance innovation with stability.
- Using proactive monitoring and alerting to detect and resolve issues before they impact users.
- Implementing self-healing mechanisms to automatically recover from failures.
Why is SRE important for businesses?
- SRE helps businesses by:
- Reducing downtime and improving system availability.
- Automating repetitive operational tasks.
- Enhancing incident management and faster recovery.
- Optimizing performance and cost efficiency.

Our Services
Location
D 210, 2nd Floor,
Titanium Business Park,
B/H Sammet Platinum,
Off. Corporate Road,
Ahmedabad - 382210
Gujarat, IN.