Karpenter Consolidation
Karpenter is a Kubernetes cluster auto scaler that helps manage node resources efficiently. While it doesn’t directly facilitate consolidation, you might want documentation on how to incorporate Karpenter into your consolidation efforts within a Kubernetes environment.
Here’s a basic outline for such documentation:
Overview:
Workload consolidation in Karpenter involves rearranging application pods across worker nodes to maximize resource utilization.
The primary goal is to reduce wastage by consolidating pods into a smaller number of nodes with the right capacity, thereby improving cluster efficiency.
Understanding Karpenter Cluster Consolidation:
Karpenter actively decreases cluster expenses by detecting:
- A scenario where nodes have no resources or objects, allowing their removal.
- Situations in which workloads on certain nodes can be shifted to other nodes with free space, enabling the removal of unnecessary nodes.
These are cases where nodes can be swapped with more cost-effective node(i.e., higher or lower VM family) options in response to workload adjustments.
Two methods for cluster consolidation
- Deletion: A node becomes eligible for removal if the available capacity of other nodes within the cluster can accommodate all its pods.
Example: Let’s say we have 3 nodes in our cluster with 50% of resources(i.e., CPU % memory) utilized. So, with the deletion method, one of the nodes will schedule all of its resources on other nodes, and the node left without any objects will be destroyed, helping us save costs. Overall, we will have 2 nodes instead of 3.
- Replace: Substitute an entire node at a lower cost when all of its workload can be placed on other nodes using a combination of available capacity on other nodes in the cluster.
Example: Assume we still have 3 nodes in our cluster with 50% of resources(i.e., CPU % Memory) utilized. So, with the replace method, one node will schedule half or all of its workloads to another, and instead of destroying itself, it will update its VM family to save cost. Overall, we still have 3 nodes but less cost usage than before.
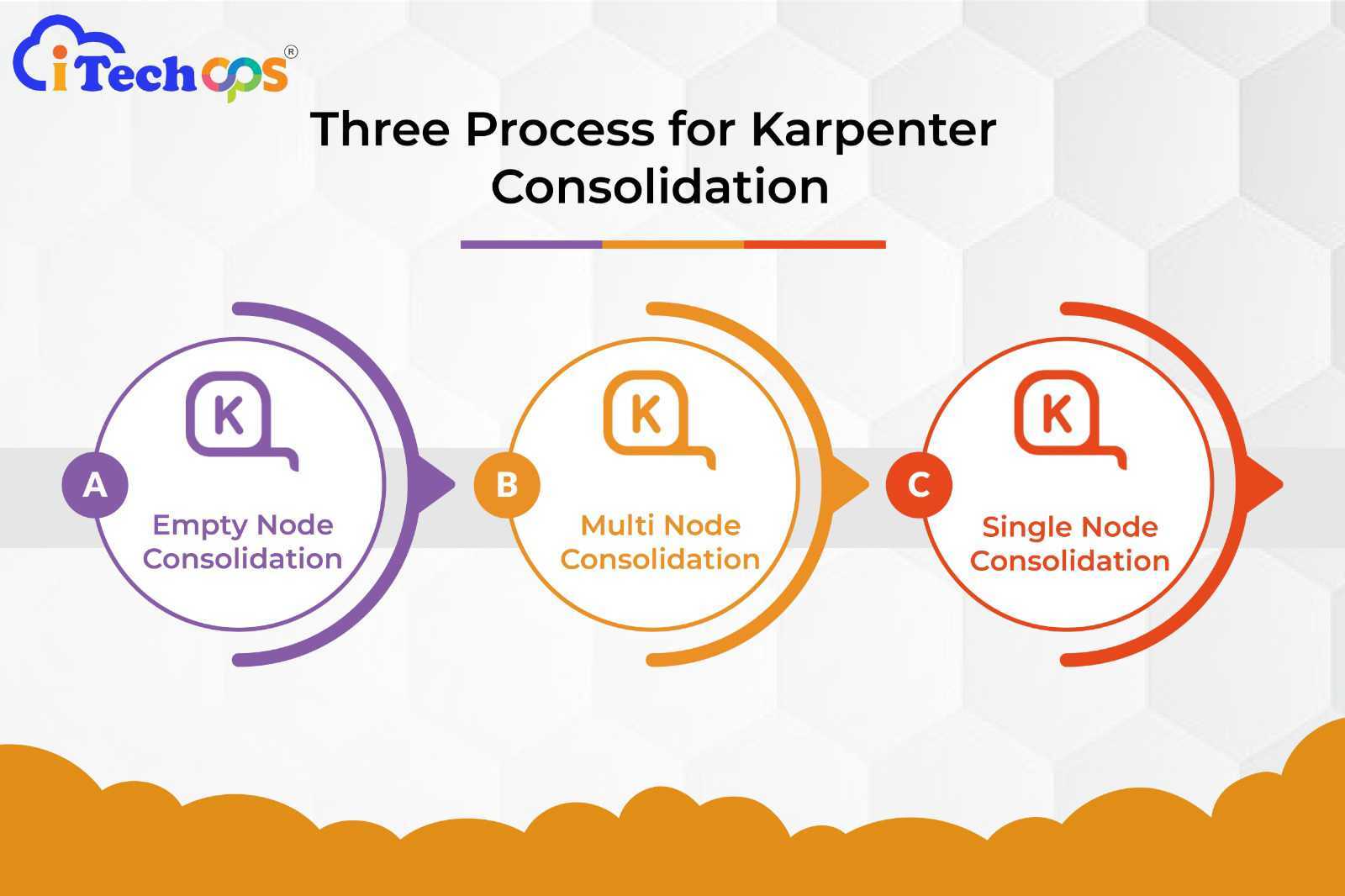
Three processes aimed at identifying consolidation actions
- Empty Node Consolidation: Simultaneously remove any empty nodes.
- Multi-Node Consolidation: Attempt to remove two or more nodes simultaneously, potentially introducing a single replacement node with a lower price compared to all nodes being removed.
- Single Node Consolidation: Endeavor to remove any single node, potentially introducing a single replacement node with a lower price compared to the node being removed.
When faced with multiple nodes eligible for deletion or replacement, Karpenter prioritizes consolidation by selecting the node that minimally disrupts workloads. It does so by favoring the termination of:
- Nodes hosting fewer pods.
- Nodes with impending expiration.
- Nodes running lower-priority pods.
NOTE:
Consolidation can be compromised if below are configured:
- PodDisruptionBudget: If PDB is configured and other nodes cannot hold the minimum workload specified by disruption policy.
- Node Taints: If nodes have taint configured on them, then workloads that don’t match their toleration will not proceed further with consolidation.
How to implement Consolidation in Azure AKS
The Consolidation policy is configured under the disruption section of the NodePool Manifest file. Let’s go through the manifest:
cat <<EOF | kubectl apply -f –
—
apiVersion:karpenter.sh/v1beta1
kind: NodePool
metadata:
name: general-purpose
annotations:
kubernetes.io/description: “General purpose NodePool for generic workloads”
spec:
template:
spec:
requirements:
– key: kubernetes.io/arch
operator: In
values: [“amd64”]
– key: kubernetes.io/os
operator: In
values: [“linux”]
– key: karpenter.sh/capacity-type
operator: In
values: [“on-demand”]
– key: karpenter.azure.com/sku-family
operator: In
values: [D]
nodeClassRef:
name: default
limits:
cpu: 100
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: Never
—
apiVersion:karpenter.azure.com/v1alpha2
kind: AKSNodeClass
metadata:
name: default
annotations:
kubernetes.io/description: “General purpose AKSNodeClass for running Ubuntu2204 nodes”
spec:
imageFamily: Ubuntu2204
EOF
Explanation
When you configure Karpenter with a disruption policy, such as consolidationPolicy: WhenUnderutilized and expireAfter: Never, it means that Karpenter will continuously monitor node utilization. If it detects underutilization, it will consolidate pods onto fewer nodes without any time limit on while implementation of this policy.
In this context, expireAfter: Never ensures that Karpenter’s consolidation policy remains in effect indefinitely, meaning it will continue to optimize node usage without any automatic expiration of the disruption budget.
There are other options as well for consolidation; let’s have a look at them:
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 720h
with this configuration, Karpenter will continuously monitor node utilization and consolidate pods onto fewer nodes when underutilized. However, it will only do so within the constraints of the disruption budget, which will remain valid for 30 days before requiring renewal or refreshment.
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 30m
When a node in the Azure Kubernetes Service (AKS) cluster becomes empty (i.e., no pods are scheduled on it), Karpenter waits for 30 minutes (consolidateAfter: 30m). After the specified waiting period, Karpenter begins consolidating the node within the AKS cluster.
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 720h
budgets:
– nodes: “20%”
– nodes: “6”
– nodes: “0”
schedule: “@daily”
duration:10m
Here, we have added a new section called budgets under disruption, which consolidates nodes if they meet the conditions provided in the budgets section.
Example: Let’s say we have 20 nodes in our cluster. So, according to the nodes: 20% budget, only 4 nodes can be consolidated if they are underutilized. Second, the budget (.ie. nodes: 6) acts as a ceiling to the previous budget, and it will consolidate 6 nodes out of 30. The last will not tolerate any consolidation for the first 10 minutes every day.
You can check the event that happened with the node pool by running the below command:
Kubectl describes nodepool general-purpose
Below is the short output:
The event describes that nodes failed to consolidate(i.e., delete or replace) to do podDisruptionBuget configured on one of the deployment or statefulsets.
Warning:
spec:
disruption:
consolidationPolicy: WhenUnderutilized
consolidateAfter: 10m
consolidateAfter cannot be used if policy set to WhenUnderutilized; instead, use WhenEmpty
References:
https://karpenter.sh/docs/concepts/disruption/#disruption-budgets
https://github.com/Azure/karpenter-provider-azure
https://github.com/kubernetes-sigs/karpenter/issues/735
https://karpenter.sh/docs/concepts/disruption/#consolidation
0 Comments