GitOps Explained: The Future Of Infrastructure Automation
Infrastructure management has become significantly more complex than it was a few years ago. Modern cloud environments are no longer static systems that change occasionally. Applications are deployed continuously, infrastructure scales dynamically, and configurations evolve across multiple environments at the same time.
As this complexity increases, manual infrastructure management starts creating operational problems. Teams make direct changes in production to resolve urgent issues, environments slowly drift away from their original configuration, and deployment processes become inconsistent across systems. In many organizations, the issue is not a lack of automation, but the lack of a reliable process that keeps infrastructure aligned over time.
This is where GitOps changes the approach completely.
Instead of treating infrastructure management as a series of manual operational tasks, GitOps turns infrastructure into a version-controlled workflow managed through Git repositories. Infrastructure changes are handled the same way application code changes are handled, with versioning, review processes, automated reconciliation, and rollback capability.
The result is not just better automation, but better operational control.
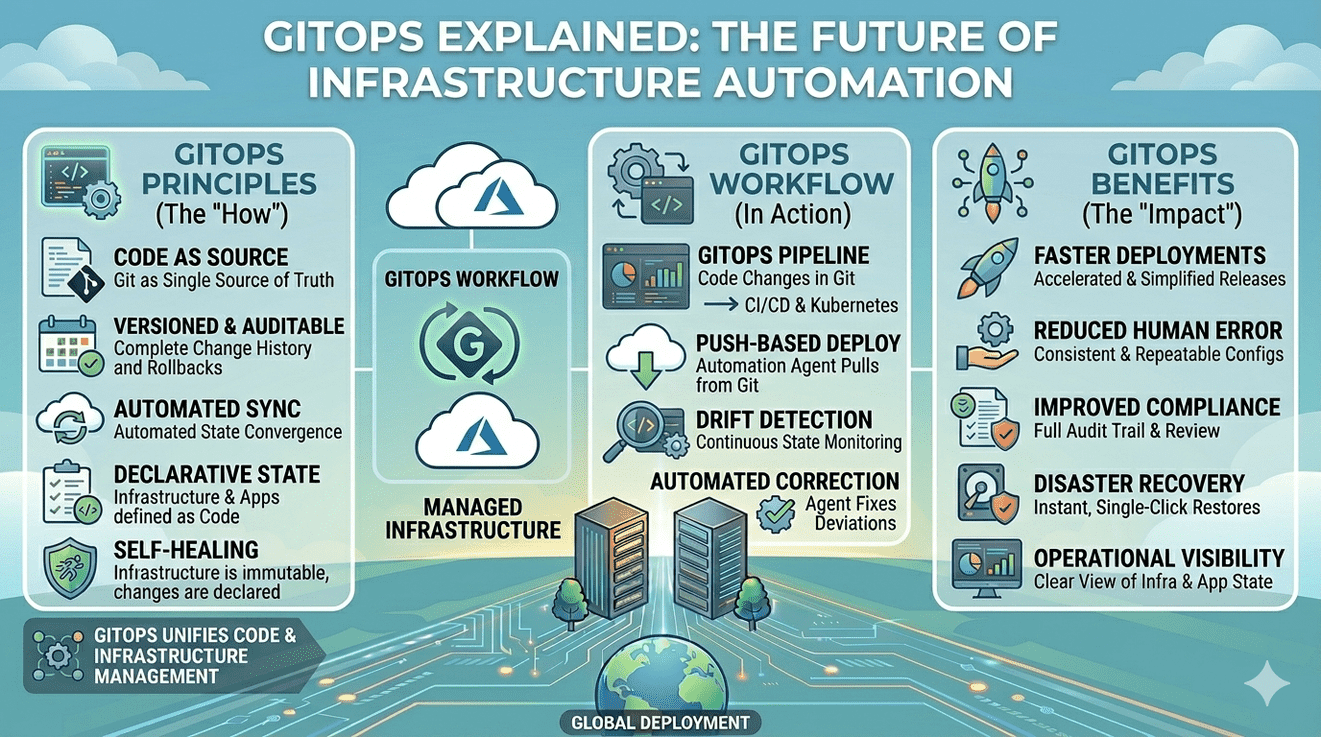
What GitOps Actually Means
GitOps is often explained as “using Git for infrastructure,” but that definition barely scratches the surface. In practice, GitOps changes how infrastructure updates are managed, approved, deployed, and monitored.
Git Becomes The Single Source Of Truth
In traditional infrastructure management, there is often a disconnect between what teams think the environment looks like and what actually exists in production. Manual changes, emergency fixes, and undocumented updates gradually create inconsistencies between environments.
GitOps solves this problem by making Git repositories the authoritative source of infrastructure configuration. The desired state of systems is stored declaratively inside version-controlled repositories, and environments continuously reconcile themselves against that state.
This creates a much more predictable operational model because infrastructure behavior is defined centrally instead of being scattered across manual changes and undocumented processes.
Infrastructure Changes Become Traceable And Auditable
One of the biggest operational problems in large cloud environments is visibility. When something breaks, teams often struggle to identify which change caused the issue, who made it, and whether the same change exists in other environments.
GitOps improves this by treating infrastructure changes exactly like software changes. Every modification goes through Git, which means changes are versioned, reviewable, and fully traceable. Teams can see who approved the update, when it was deployed, and how the configuration evolved over time.
This level of traceability becomes especially important in enterprise environments where compliance, governance, and auditability are critical operational requirements.
Automation Replaces Manual Infrastructure Updates
Manual infrastructure management becomes increasingly unreliable as systems scale. Even experienced teams make mistakes when configuration updates are applied directly across multiple environments. Small inconsistencies eventually create deployment issues and operational instability.
GitOps reduces this dependency on manual execution by automating how infrastructure changes are applied. Once configuration updates are approved in Git, automated agents reconcile the environment to match the declared state.
This ensures that deployments happen consistently every time rather than depending on manual operational processes that vary between teams or environments.
Why Traditional Infrastructure Management Creates Problems
GitOps gained momentum because traditional infrastructure workflows struggle to handle the speed and scale of modern cloud systems.
Configuration Drift Slowly Creates Instability
Configuration drift is one of the most common operational problems in cloud infrastructure. It happens when environments slowly move away from their intended configuration because of manual updates, quick fixes, or undocumented changes.
For example, an engineer may modify production settings during an incident to restore service quickly. The issue gets resolved, but the change is never reflected in infrastructure repositories or deployment pipelines. Over time, these small inconsistencies accumulate, and environments stop behaving predictably.
The result is that deployments become riskier because staging and production environments are no longer aligned. Teams may validate updates successfully in one environment only to experience failures in another because configurations differ in ways nobody fully understands.
Manual Deployments Create Operational Bottlenecks
As systems scale, manual deployment processes become difficult to manage consistently. Infrastructure updates may require coordination across multiple teams, approvals may happen outside structured workflows, and deployment execution often depends on specific engineers being available.
This slows down delivery and increases operational risk because the process itself becomes dependent on human coordination rather than automation. Even small deployment mistakes can affect production systems when infrastructure updates are applied manually across environments.
GitOps reduces these bottlenecks by introducing standardized workflows where deployments follow repeatable automated processes instead of relying on operational improvisation.
Recovering From Failures Becomes Harder
Infrastructure recovery becomes significantly more difficult when environments are not version-controlled properly. Teams may know that something changed, but they often lack visibility into exactly what changed or how to restore a previously stable configuration.
This becomes especially problematic during incidents where rapid rollback is required. Without clear version history and centralized configuration management, recovery depends heavily on tribal knowledge and manual troubleshooting.
GitOps improves this by ensuring that infrastructure history exists inside version-controlled repositories, making rollback and recovery far more reliable.
Example: When Configuration Drift Breaks Production
A platform engineering team manages Kubernetes infrastructure for multiple applications. During a production incident, an engineer directly modifies cluster configuration to stabilize one service experiencing resource issues. The fix works, traffic normalizes, and the incident is resolved quickly.
However, the infrastructure repository is never updated with the same configuration change.
A few weeks later, a new deployment is triggered through the CI/CD pipeline. Since the deployment uses the original Git configuration, the production cluster is automatically reconciled back to the outdated state. The previous fix disappears, resource limits change unexpectedly, and application instability returns.
The issue was not the deployment itself. The problem was that production no longer matched the declared infrastructure state.
In a properly implemented GitOps workflow, direct production changes would either be restricted entirely or automatically flagged as drift, preventing this type of inconsistency from accumulating unnoticed.
Core Principles Behind GitOps
GitOps works because it follows a small set of operational principles that improve consistency and reduce infrastructure unpredictability.
Declarative Infrastructure Simplifies Automation
Traditional infrastructure management often depends on procedural execution, where engineers manually run commands to create or modify environments. This works at smaller scales, but becomes difficult to manage consistently across large distributed systems.
GitOps uses declarative infrastructure instead. Teams define the desired end state of systems rather than manually describing every operational step needed to achieve it. Deployment systems then reconcile the actual environment against that desired state automatically.
This approach simplifies automation because infrastructure tools no longer depend on manual execution logic. Instead, they continuously work toward maintaining the correct system state.
Version Control Creates Operational Stability
Version control is not just about tracking changes. In GitOps, it becomes the operational foundation for infrastructure management. Every update follows a structured workflow that includes review, approval, validation, and deployment tracking.
This dramatically improves operational stability because infrastructure changes become predictable and repeatable. Teams gain visibility into deployment history, rollback capability becomes easier, and troubleshooting becomes faster because the system state is fully documented through Git history.
Automated Reconciliation Prevents Drift
One of the defining characteristics of GitOps is continuous reconciliation. Automated agents constantly compare the running environment against the declared state stored in Git repositories.
If drift occurs because of manual updates or unexpected changes, the system automatically restores the intended configuration. This prevents environments from slowly diverging over time and ensures operational consistency across deployments.
Why GitOps Fits Modern Cloud Infrastructure
Modern infrastructure changes too quickly for manual operational models to remain reliable.
Cloud-native environments rely heavily on:
- Kubernetes clusters
- microservices architectures
- dynamic scaling
- frequent deployments
In these systems, infrastructure changes happen continuously, and operational consistency becomes difficult to maintain through manual coordination alone.
GitOps fits naturally into this environment because it combines automation, version control, and declarative infrastructure management into a workflow designed for continuous change rather than static operations.
How GitOps Improves Infrastructure Automation
Traditional automation reduces manual work, but GitOps improves something more important: operational consistency.
Deployments Become More Predictable
In many organizations, deployment reliability depends heavily on operational coordination. Different engineers may follow slightly different processes, environments may contain undocumented changes, and infrastructure behavior can vary between staging and production.
GitOps reduces this unpredictability by standardizing how deployments happen. Since infrastructure changes are applied through version-controlled workflows, deployments follow the same process every time.
This consistency becomes extremely valuable in large environments where even small configuration differences can create deployment failures or unexpected behavior during releases.
Rollbacks Become Faster And Safer
One of the biggest operational advantages of GitOps is rollback capability. In traditional infrastructure management, reverting problematic changes often involves manual troubleshooting and reconfiguration under pressure.
With GitOps, rollback becomes significantly simpler because previous infrastructure states already exist in version control. Teams can revert infrastructure to a known stable configuration directly through Git history instead of manually reconstructing the environment.
This reduces recovery time during incidents and lowers the operational stress associated with failed deployments.
Multi-Environment Management Becomes Easier
Managing development, staging, and production environments manually often creates inconsistencies over time. Small configuration differences accumulate gradually, and environments stop behaving the same way.
GitOps improves this by managing environments through centrally versioned configuration. Teams can define environment-specific behavior while still maintaining overall consistency across deployments.
This reduces the “works in staging but fails in production” problem that many organizations struggle with as infrastructure complexity increases.
Why GitOps Works Well With Kubernetes
GitOps adoption increased significantly alongside Kubernetes because both approaches align naturally with declarative infrastructure management.
Kubernetes Already Uses Declarative Models
Kubernetes infrastructure is defined declaratively through YAML manifests that describe the desired state of clusters, services, and workloads. GitOps builds directly on this concept by storing those declarations inside Git repositories and automating reconciliation.
This creates a workflow where Kubernetes continuously aligns itself with the desired configuration stored in Git, reducing the need for manual cluster management.
Dynamic Environments Need Continuous Reconciliation
Kubernetes environments change constantly. Pods restart, workloads scale dynamically, and services evolve continuously. Managing these systems manually quickly becomes difficult because the environment itself is highly dynamic.
GitOps fits this model because reconciliation is continuous rather than event-based. Automated agents constantly monitor cluster state and ensure it matches the desired configuration stored in repositories.
This reduces operational drift and improves infrastructure stability even as systems scale rapidly.
Infrastructure And Applications Follow The Same Workflow
Traditionally, infrastructure teams and development teams often follow separate operational processes. GitOps helps unify these workflows because both infrastructure and applications are managed through version-controlled repositories.
This alignment simplifies collaboration between teams and creates more consistent deployment practices across the organization.
Pull-Based Deployment Changes How Infrastructure Is Managed
One of the defining characteristics of GitOps is the pull-based deployment model.
Traditional CI/CD Pipelines Push Changes Into Environments
In many CI/CD workflows, deployment systems push updates directly into infrastructure environments. While effective, this approach requires deployment systems to maintain elevated access into production systems.
As environments scale, managing these permissions becomes increasingly complex and creates additional security concerns.
GitOps Uses Pull-Based Reconciliation Instead
In a GitOps model, deployment agents running inside the environment pull approved configuration changes from Git repositories. Instead of external systems pushing updates inward, the environment continuously reconciles itself against the declared state.
This improves security because production environments no longer require broad inbound administrative access for deployments. It also improves operational reliability because reconciliation happens continuously rather than only during deployment events.
Operational Challenges Organizations Face With GitOps
GitOps improves consistency, but it also introduces operational challenges that teams need to manage carefully.
Repository Structures Can Become Difficult To Manage
As infrastructure grows, repositories often become increasingly complex. Multiple teams may manage shared environments, different services may require separate deployment workflows, and configuration sprawl can make repositories difficult to navigate.
Without clear standards for repository organization, GitOps environments can become operationally difficult to maintain even if deployments remain automated.
Managing Secrets Requires Additional Planning
Infrastructure configurations often depend on sensitive information such as API keys, database credentials, or certificates. Storing this information directly inside repositories creates obvious security risks.
Organizations adopting GitOps need secure methods for managing secrets separately while still integrating them into automated deployment workflows. This typically requires additional tooling and operational processes beyond basic GitOps implementation.
Teams Need Strong Operational Discipline
GitOps works best when teams follow structured operational practices consistently. Direct production changes, undocumented fixes, or bypassing Git workflows can quickly undermine the benefits of the model.
This means GitOps adoption is not just a tooling change, but also a cultural and operational shift. Teams need to trust automated workflows and commit to using version-controlled processes consistently.
Example: When GitOps Improves Incident Recovery
A SaaS company deploys a configuration update that unintentionally changes traffic routing behavior inside its Kubernetes environment. Within minutes, users begin experiencing intermittent application failures.
In a traditional setup, engineers would need to manually identify which configuration changed, recreate the previous state, and carefully apply rollback updates under pressure. This process could take significant time, especially if infrastructure changes were not documented clearly.
In a GitOps workflow, the deployment history already exists inside Git repositories. Teams quickly identify the problematic configuration update, revert the commit, and allow automated reconciliation to restore the previous stable state.
The recovery process becomes faster not because incidents stop happening, but because infrastructure history and rollback capability already exist as part of the workflow.
Role Of Monitoring And Incident Visibility In GitOps
Automation improves consistency, but visibility remains critical when deployments fail or infrastructure behaves unexpectedly.
Teams need visibility into:
- deployment timing
- infrastructure changes
- reconciliation failures
- system behavior after updates
Without centralized visibility, troubleshooting GitOps environments can become difficult because changes occur continuously across distributed systems.
Platforms like itechops help teams centralize alerts and incidents across environments, making it easier to identify deployment-related issues and correlate infrastructure events during operational incidents.
Best Practices For Implementing GitOps
GitOps adoption works best when organizations focus on operational discipline rather than tooling alone.
Standardize Repository Structures Early
Repository organization becomes increasingly important as systems scale. Clear standards for how infrastructure configurations are structured reduce confusion and improve maintainability across teams.
Validate Infrastructure Changes Automatically
Infrastructure updates should go through automated validation and testing before deployment. This reduces the likelihood of unstable configurations reaching production environments.
Avoid Direct Production Changes
Direct modifications inside production environments create drift and undermine GitOps workflows. Teams should treat Git repositories as the only approved path for infrastructure updates.
Start With Smaller Systems First
Organizations often achieve better results by introducing GitOps gradually rather than attempting full-scale adoption immediately. Smaller deployments allow teams to refine workflows before scaling operational complexity.
Why GitOps Is Becoming The Future Of Infrastructure Automation
Modern cloud infrastructure changes too rapidly for manual operational models to remain reliable. Systems are increasingly distributed, deployments happen continuously, and environments evolve dynamically across cloud platforms.
GitOps addresses this reality by combining:
- declarative infrastructure
- version-controlled workflows
- automated reconciliation
- deployment consistency
Instead of depending on manual coordination between teams, infrastructure management becomes predictable and repeatable.
This shift is why GitOps is increasingly becoming a foundational operational model for cloud-native infrastructure rather than just another DevOps practice.
Conclusion
GitOps transforms infrastructure management from a manual operational process into a structured, automated workflow built around version control and continuous reconciliation.
By making Git the source of truth, organizations gain better visibility into infrastructure changes, improved deployment consistency, and faster recovery during incidents. At the same time, automation reduces operational overhead and helps teams manage increasingly complex cloud environments more reliably.
As cloud infrastructure continues to scale, GitOps is likely to become less of an optional operational model and more of a standard approach for managing infrastructure automation at scale.

0 Comments